Eine kleine Vorwarnung, der folgende Artikel hat wahrscheinlich nur sentimentalen Wert für mich. Ich möchte mich erst einmal bei Martin bedanken, dass er mich via Jabber ausgehalten hat. Es ist etwas über 10 Jahre her, dass ich mein Diplomarbeit mit dem Thema Vergleich von kommunizierenden Prozessen und Kaktusstack auf Mehrkernarchitekturen abgeben habe. Eines Abends bin ich auf die Idee gekommen, dass ich den meine Lösungen mit dem Kaktusstack auf heutigen Prozessoren noch einmal ausprobiere. Das ganze hat keinen Anspruch auf Korrektheit, da dieser Artikel das Ergebnis von nur 2 Abenden ist. Ich habe alles nur einmal laufen lassen, d.h. ich habe meine Ergebnisse weder verifizieren lassen noch habe ich sie selbst verifiziert.
Eine Idee meiner Diplomarbeit war, dass man die breite verfügbaren Mehrkernprozessoren nutzt, um Probleme schneller und effizient zu lösen. Unter günstigen Bedingungen habe ich damals auch einen superlinearen Speedup erreicht. Wenn ich ehrlich bin, habe ich damals sehr getunt, damit ich das letzte Quäntchen an Effizienz aus der Implentierung hole.
Auf einem System mit 2 Intel Xeon X5570 sowie 48 GB RAM habe ich die folgenden Ergebnisse erzielt:
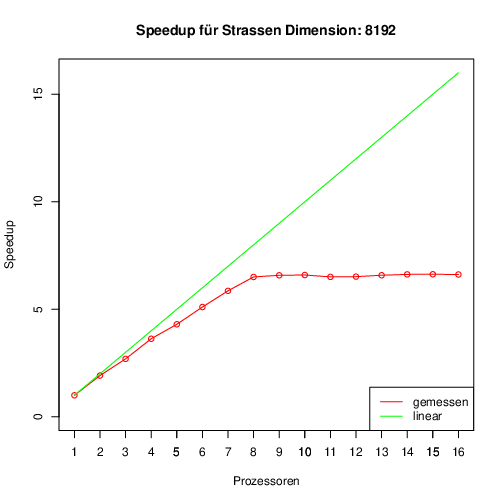
Dabei handelt es sich um die Ergebnisse der Matrixmultiplikation nach Strassen mit vollbesetzten 8192x8192 Matrizzen. Damals habe die Algorithmen mit Cilk++ umgesetzt. Kurze Zeit später wurde das Cilk(++) salonfähig, Intel hat sich darum gekümmert und es wurde auch Bestandteil vom gcc. Deswegen dachte ich, dass mein alter Code von damals noch laufen müsste. Dann kam die Ernüchterung, Cilk ist nicht mehr Bestandteil vom gcc1, weil es niemand benutzt hat. Mein Code ließ sich mit einem gcc 7.5 nicht übersetzten, da musste ich noch ein paar Anpassungen machen. Das nächste Problem war, dass meine Toolchain etwas aus der Hölle war. Nach etwas Arbeit habe ich es verstanden. Anschließend habe ich die das ganze auf meinen AMD Ryzen 7 2700 mit 32 GB RAM und einem AMD Epyc 7502P mit 128 GB RAM laufen lassen. Aktuelle Prozessoren takten viel dynamischer als die Xeon X5570.
Das sind die Taktraten, welche ich auf meinem Ryzen 7 2700 während der Berechnung beobachtet habe.
| aktive Threads | Takt in MHz |
|---|---|
| 1 | 4024 |
| 2 | 3965 |
| 3 | 3848 |
| 4 | 3728 |
| 5 | 3663 |
| 6 | 3571 |
| 7 | 3472 |
| 8 - 16 | 3361 |
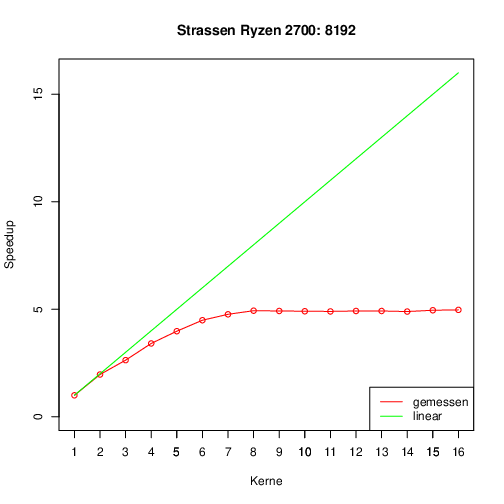
Man sieht hier, dass der Speedup nicht so gut ist, wie bei dem Xeon System. Ein Grund wird sein, dass die beiden Xeon X5570 bis 4 Threads den vollen Takt haben. Wenn 3 - 8 Threads auf einer CPU laufen fällt der Takt von 3333 auf 2933 MHz. Man kann eine CPU auch auf einen festen Takt setzen. Das überlasse ich anderen Leuten.
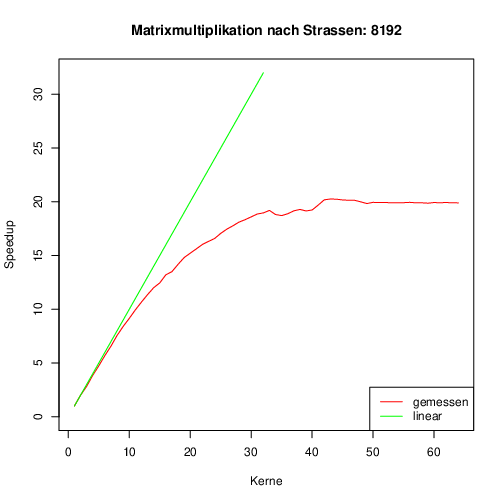
Hier sieht man, dass die Implentierung bis ca. 20 Threads gut skaliert. Der Epyc 7502P taktet auch dynamsich. Der Knick zwischen 30 und 40 Threads kommt dadurch zustande, dass ich das System nicht exklusiv zur Verfügung hatte.
Ergebnis
Die CPUs sind ohne großartige Taktsteigerungen schneller geworden:
| CPU | Takt in MHz | Leufzeit 1 Thread |
|---|---|---|
| Xeon X5570 | 3333 | 140s |
| Epyc 7502P | 3324 | 70s |
| Ryzen 2700 | 4024 | 52s |
Hyperthreading funktioniert heute so schlecht/gut wie damals. Man wird bei dieser Implementierung durch die zusätzlichen Threads nichts schneller, aber auch nicht langsamer. Der prinzielle Ansatz zur Parallelisierung von Algorithmen funktioniert auch heute noch und es skaliert auch gut.
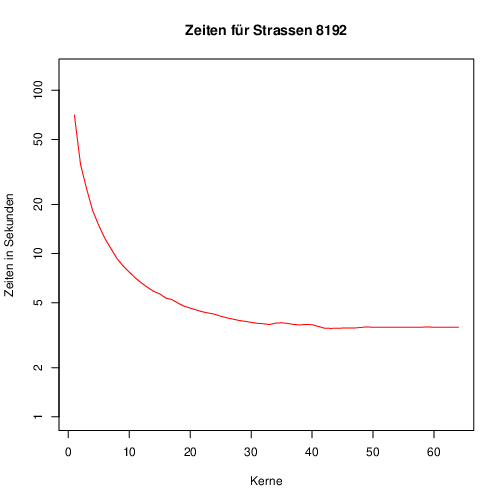
Wenn man sich die Zeiten anschaut, dann wird man ab 12 Threads nicht mehr signifikant besser. Daraus folgt, wie schon vor 10 Jahren, dass man lieber guten sequenziellen Code schreiben sollte. Bei kleinen Problemen erzielt man ab einen gewissen Punkt kaum noch ein praktische Verbesserung der Laufzeit. Ich finde es sehr schade, dass Cilk und damit der Kaktusstack wahrscheinlich tot ist. Aber viel schlimmer finde ich, dass ich meine 12 Threads im Laptop nicht reichen um eine Electron App auszuführen. Meine Implementierung des Algorithmus von Strassen erzeugt fast die gleiche Last wie Teams und braucht fast so vie RAM wie mein Browser.
Wenn ich Martin mal wieder auf die Ketten gehe, dann kann ich das ganze mal mit AVX oder OpenMP oder mit go versuchen. Alternativ kann ich es als Elektron App bauen. :D